Cyber Security News Aggregator
.Cyber Tzar
provide acyber security risk management
platform; including automated penetration tests and risk assesments culminating in a "cyber risk score" out of 1,000, just like a credit score.
First slide label
Some representative placeholder content for the first slide.
Second slide label
Some representative placeholder content for the second slide.
Third slide label
Some representative placeholder content for the third slide.
How Much Your Org Reaction to a Tweet Says?
published on 2017-05-07 21:51:27 UTC by Carlos PerezContent:
Recently Tavis Ormandy a well known vulnerability researcher from Google made a tweet about a vulnerability he and researcher Natalie Silvanovich from Google Project Zero found on the Windows OS that could be wormable.
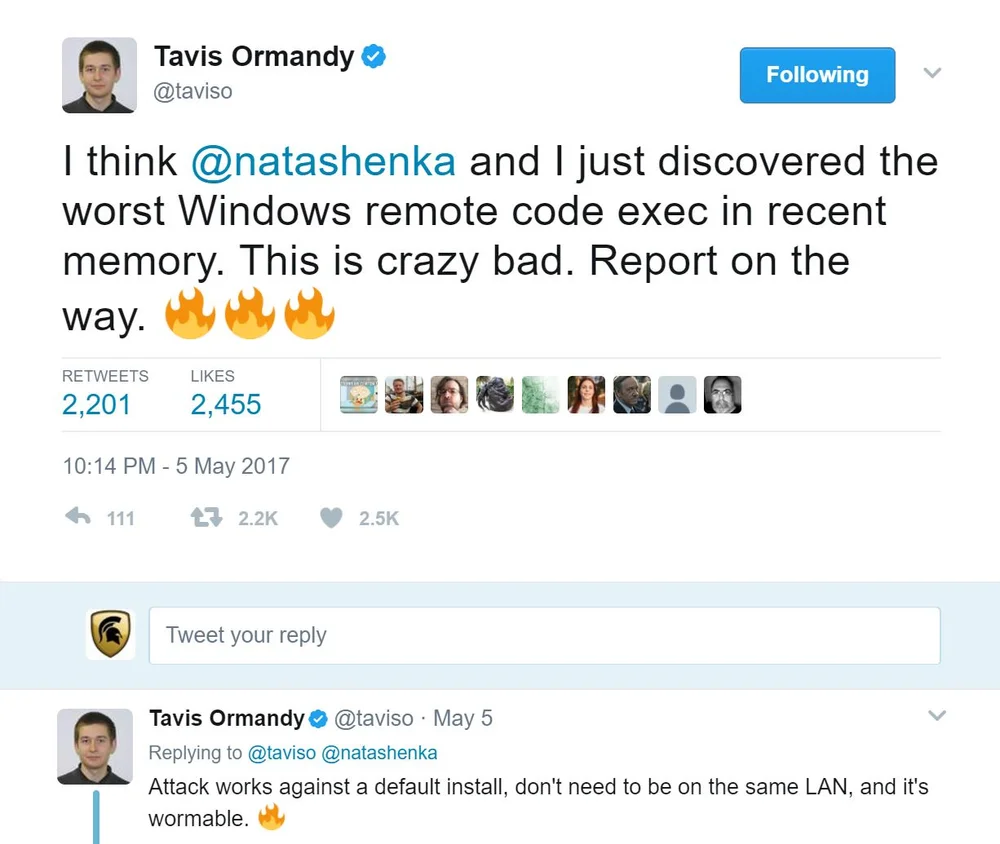
The reaction from many organizations has been from one extreme all the way to the other side, where some are panicking and to the other side they simply take it as a nice to know heads up. So what is the difference between this different organizations? I would say a lot.
In security the new notion has been to always assume breach and with the new DevOps mantra taken by many organization having constant telemetry and automation has lead to many organizations to be better prepared for this type of bug being made public. Sadly the reasons for this is not security but to be better able to meet demand in a rapid changing market, but the majority of organizations are not like this.
When a high impact vulnerability surfaces or ganizations with a deep knowledge of their environment are better prepared to handle this situation. Let me explain some of the main areas that makes them better prepared.
The first step is to identify all assets in the network
- Servers
- Desktops
- Printers
- Switches
- Access Points
- Routers
- Any other device with an IP Address.
Once we have our assets identified it is of great importance to understand the network and where they sit. This is important because many times this information is not correct in many organizations.
- Logical Network Diagram
- Traffic Flow between segments
Now that we have identified this information we must have an inventory of each device:
- What OS is it running.
- What is the patch level of each device.
- What firmware components and their versions (Remember Intel AMT, ASA and JunOS vulns)
- What applications are installed on the host.
One part that is also not mastered by many is having documentation of how each host is configured. Many vulnerabilities are mitigated by configuration parameters even when the patch is not installed or available. Many organizations are moving to a DevOps model where configuration is managed in a central place either using Chef, Puppet, Ansible, DSC and many others either standalone of a mix of them. Having a centralized configuration management system allows to document configurations and take critical decisions quickly to identify risk and respond to it.
One part missing if footprint, what services are exposed on the devices, many times just because a service is enabled does not mean it is available, so having both a footprint view of the system from the network and locally is important since most modern operating system now include firewalls and they can alter the attack surface of the host.
Now all of this seems basic but many organizations miss the basic part of knowing what is their environment, what composes it and how it works. It is not new that new high impact vulnerabilities surface several times a year, yet still many lack the processes in place to deal with one. A basic example process would be to have the management and team leads of the groups that are responsible for the management and key management sponsors form part of a communication process for when a vulnerability of high impact comes out it can quickly be relayed to every key decision maker and ensure a rapid decision for a course of action on the evaluation of it is taken. Once a decision is made to patch because the risk is real and business agrees with the impact of the process the key components of the organization that pose the greatest impact based on the risk model of the vulnerability will be patched first after tests and validations are done in a test environment first. Here is where proper planning comes it to play, if testing has been automated and improved on a regular basis as the process if used and new areas of improvement are identified the testing will minimize most risks and doubts that the business side of the organization may have. The patch is deployed after those systems have been backed up and then the rest of the organization. It is important to have a centralized logging system so as to be able to monitor for possible problems and have a help desk process that will help triage and escalate the issues quickly.
In an organization with the invested capital in security operations will have a Blue and Red Team in this case both teams should have a table top exercise to look at tools, exploits and discuss tradecraft around how the vulnerability can be leverage, Red will bring their unique skills in devising several ways how it would use and blue will work with them so as to identify how it can be monitored for and mitigated validating with the Red team how much of an impact it would cause to anyone leveraging the vulnerability. This will also include the identification of tooling that may surface and if it adds any unique traits to what it can be seen to detect.
Last part once the event is done with a post-mortem or review should be done to identify what can be improved on, test and validate assumption, and modifying the plan for the next one. In an organization that follow these basics like many do this kind of situations are handled quickly with little stress to those involved.
The question is if your organization ready? if not start working on it, the clock is ticking, no excuses to prepare, every year we see many of this cases and there will always be more of them.
https://www.darkoperator.com/blog/2017/5/7/how-much-your-org-reaction-to-a-tweet-says
Published: 2017 05 07 21:51:27
Received: 2023 11 17 05:03:37
Feed: Blog
Source: Blog
Category: Cyber Security
Topic: Cyber Security
Views: 3
