Cyber Security News Aggregator
.Cyber Tzar
provide acyber security risk management
platform; including automated penetration tests and risk assesments culminating in a "cyber risk score" out of 1,000, just like a credit score.
First slide label
Some representative placeholder content for the first slide.
Second slide label
Some representative placeholder content for the second slide.
Third slide label
Some representative placeholder content for the third slide.
We're Backfilling and Cleaning Stealer Logs in Have I Been Pwned
published on 2025-03-04 04:45:19 UTC by Troy HuntContent:

I think I've finally caught my breath after dealing with those 23 billion rows of stealer logs last week. That was a bit intense, as is usually the way after any large incident goes into HIBP. But the confusing nature of stealer logs coupled with an overtly long blog post explaining them and the conflation of which services needed a subscription versus which were easily accessible by anyone made for a very intense last 6 days. And there were the issues around source data integrity on top of everything else, but I'll come back to that.
When we launched the ability to search through stealer logs last month, that wasn't the first corpus of data from an info stealer we'd loaded, it was just the first time we'd made the website domains they expose searchable. Now that we have an actual model around this, we're going to start going back through those prior incidents and backfilling the new searchable attributes. We've just done that with the 26M unique email address corpus from August last year and added XXX new instances of an email address mapped against a website domain. We've also now flagged that incident as "IsStealerLog" so if you're using the API, you'll see that attribute now set to true.
For the most part, that data is all handled just the same as the existing stealer log data: we map email addresses to the domains they've appeared against in the logs then make all that searchable by full email address, email address domain or website domain (read last week's really, really long blog post if you need an explainer on that). But there's one crucial difference that we're applying both to the backfilling and the existing data, and that's related to a bit of cleaning up.
A theme that emerged last week was that there were email addresses that only appeared against one domain, and that was the domain the address itself was on. If john@gmail.com is in there and the only domain he appears against is gmail.com, what's up with that? At face value, John's details have been snared whilst logging on to Gmail, but it doesn't make sense that someone infected with an info stealer only has one website they've logging into captured by the malware. It should be many. This seems to be due to a combination of the source data containing credential stuffing rows (just email and password pairs) amidst info stealer data and somewhere in our processing pipeline, introducing integrity issues due to the odd inputs. Garbage in, garbage out, as they say.
So, we've decided to apply some Occam's razor to the situation and go with the simplest explanation: a single entry for an email address on the domain of that email address is unlikely to indicate an info stealer infection, so we're removing those rows. And not adding any more that meet that criteria. But there's no doubt the email address itself existed in the source; there is no level of integrity issues or parsing errors that causes john@gmail.com to appear out of thin air, so we're not removing the email addresses in the breach, just their mapping to the domain in the stealer log. I'd already explained such a condition in Jan, where there might be an email address in the breach but no corresponding stealer log entry:
The gap is explained by a combination of email addresses that appeared against invalidly formed domains and in some cases, addresses that only appeared with a password and not a domain. Criminals aren't exactly renowned for dumping perfectly formed data sets we can seamlessly work with, and I hope folks that fall into that few percent gap understand this limitation.
FWIW, entries that matched this pattern accounted for 13.6% of all rows in the stealer log table, so this hasn't made a great deal of difference in terms of outright volume.
This takes away a great deal of confusion regarding the infection status of the address owner. As part of this revision, we've updated all the stealer log counts seen on domain search dashboards, so if you're using that feature, you may see the number drop based on the purged data or increase based on the backfilled data. And we're not sending out any additional notifications for backfilled data either; there's a threshold at which comms becomes more noise than signal and I've a strong suspicion that's how it would be received if we started sending emails saying "hey, that stealer log breach from ages ago now has more data".
And that's it. We'll keep backfilling data, and the entire corpus within HIBP is now cleaner and more succinct. And we'll definitely clean up all the UX and website copy as part of our impending rebrand to ensure everything is a lot clearer in the future.
I'll leave you with a bit of levity related to subscription costs and value. As I recently lamented, resellers can be a nightmare to deal with, and we're seriously considering banning them altogether. But occasionally, they inadvertently share more than they should, and we get an insight into how the outside world views the service. Like a recent case where a reseller accidentally sent us the invoice they'd intended to send the customer who wanted to purchase from us, complete with a 131% price markup 😲 It was an annual Pwned 4 subscription that's meant to be $1,370, and simply to buy this on that customer's behalf and then hand them over to us, the reseller was charging $3,165. They can do this because we make the service dirt cheap. How do we know it's dirt cheap? Because another reseller inadvertently sent us this internal communication today:
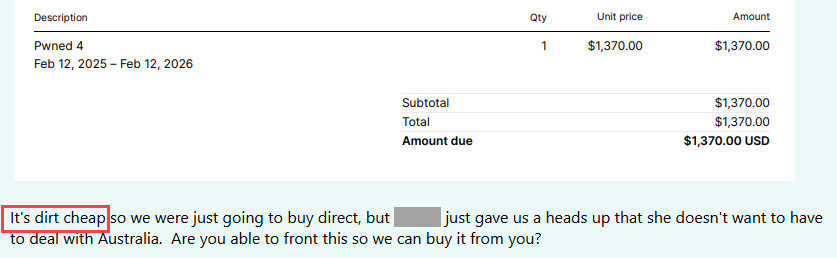
FWIW, we do have credit cards in Australia, and they work just the same as everywhere else. I still vehemently dislike resellers, but at least our customers are getting a good deal, especially when they buy direct 😊
https://www.troyhunt.com/were-backfilling-and-cleaning-stealer-logs-in-have-been-pwned/
Published: 2025 03 04 04:45:19
Received: 2025 03 04 05:38:17
Feed: Troy Hunt's Blog
Source: Troy Hunt's Blog
Category: Cyber Security
Topic: Cyber Security
Views: 21
